
One of life’s great contradictions is that you can have too much of a good thing. It’s something we all experience from time to time—too much dessert, an overplayed song, too many back-to-back reruns of “Cheers.” The point is, more isn’t always better, particularly if it’s more of the same.
This is also true of web content. While having lots of content can improve a website’s SEO, it’s not just about quantity—it’s also about variety. The content on each page should be unique, even if it references similar topics and keywords. Having multiple copies of the same content (aka duplicate content) can actually hurt SEO. “Duplicate content” refers to any instance where the same content appears on more than one unique webpage. Even if it’s well-written, as far as SEO is concerned, duplicate content is simply too much of a good thing.
The main problem posed by duplicate content is it confuses search engines. When a search engine’s crawlers encounter multiple pages with similar content, they have trouble determining which is the most authoritative and thus aren’t sure which they should assign value to for ranking purposes. Plus, when crawlers have to evaluate numerous iterations of the same content, it takes longer for them to crawl and index a site. In these ways, duplicate content can hamper a website’s search visibility and overall performance.
Examples of duplicate content
While duplicate content occurs in many forms, most instances reflect one of two circumstances. The first is when the same content appears on multiple webpages. While this can occur intentionally (the website owner publishes the same content on several pages), it can also happen without the site owner’s knowledge.
One example of the latter is when content management systems like WordPress create multiple paths for the same content in the form of category and tag archives. Because of this, a blog post about air conditioning will appear not only on its original URL, but also in the archive URLs for related categories (“HVAC”), tags (“air conditioning”) and authors.
Another example is product information pages on e-commerce sites, which allow users to sort and filter by attributes like price or brand. This function creates numerous duplicates of the original page, with only the order of products changed. While this is great for user experience, the resulting duplicate content can cause confusion for search engines about which version of the page is the most important.
The second circumstance under which duplicate content takes place is when there are multiple derivatives of a single URL. These derivatives can be generated from several sources, including:
• Inbound referral links from social media and other websites (Ex: url/?Source=Social&Site=FACEBOOK)
• User session IDs tracked by the website’s server (Ex: url/?ID=123)
• URL parameters created for tracking purposes (Ex: url/?Campaign=Google&Source=searchad)
• Printer-friendly versions of pages (Ex: url/?VER=Print)
• Multiple homepage iterations. A homepage’s www, non-www, secure-www and non-secure www forms each represent unique iterations of the entire website.
While some of these derivatives are intentionally created (i.e. URL parameters for tracking purposes), most are generated outside of the site owner’s volition. In either case, when taken altogether, the result is countless iterations of duplicate content for search engines to sort through.
Avoiding problems with duplicate content
Whether you have a personal blog or a business website, you’re going to run into problems with duplicate content, and the only way to avoid those problems is to deal with them proactively. Fortunately, you have a few tools at your disposal:
• Canonical tags
• 301 redirects
• Meta robots no index tags
Each of these tools provides a solution to duplicate content in a particular context. For the remainder of this article, we’ll talk about these tools and the situations in which they’re appropriate to use.
Canonical tags (rel=canonical)
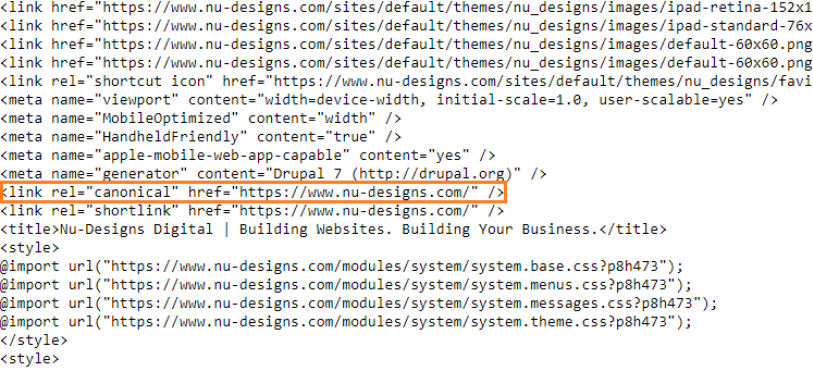
When writing a college term paper, students are expected to cite their sources, typically by inserting footnotes on pages with citations. A canonical tag does a similar thing: When a webpage contains duplicate content, it lets search engines know by “citing” the original, authoritative page.
Here’s what a canonical tag looks like in code form:

When placed in the header code of a page containing duplicate content, it tells crawlers, “I’m not the original source; this page is!” That way, the crawlers know which page they should be indexing and assigning value to.
Canonical tags are ideal for instances when user experience or analytics are a concern. They’re good for user experience because, unlike a 301 redirect (which we’ll learn about next), they don’t reroute users to a different URL. Rather, they allow duplicate content pages to remain functional while informing search engines which one is authoritative. Canonical tags also come in handy if you want to measure traffic to various duplicate content pages for analytics purposes but don’t want to confuse search engines in the process.
A good example of using canonical tags is with product information pages on e-commerce sites. All “sort” and “filter” versions of a product page should contain “rel=canonical” tags that point to the original, authoritative version of the page. This lets search engines know to index and rank that page and ignore all other versions. That way, the main product page will show up in search results, as opposed to the “price - low to high” version.
It’s worth noting that a canonical tag can also be placed in the header of an authoritative page to declare it as such. This is called a self-referencing canonical. It may seem redundant, but Google says this is worth doing to further ensure its crawlers are indexing the correct page.
You’re probably thinking, “Wow, tagging all of those pages sounds like a lot of work!” Well, you’re right. Fortunately, you can streamline this task by using a content management system like WordPress. Click here for more information on how to apply canonical tags with WordPress’ Yoast SEO plugin.
301 redirects
Whereas a canonical tag allows a duplicate content page to exist without adverse SEO consequences, a 301 redirect simply reroutes a duplicate content page to the more authoritative URL. It’s basically a more heavy-handed way of telling search engine crawlers which page they should acknowledge.
Here’s what a 301 redirect looks like in code form:

301 redirects aren’t practical for all instances. The main caveat with using them is the potential negative impact on user experience. Unlike a canonical tag, which doesn’t alter the user’s trajectory, a 301 redirect pushes users to a different page, which can be a bit jarring. Additionally, referencing the e-commerce site example again, 301 directs wouldn’t solve the problem posed by product “sort” and “filter” pages. If you used them, users attempting to sort would keep getting pushed back to the original page.
One instance where 301 redirects are useful is when your site’s structure changes—for example, when you need to remove a page. That way, if someone tries to visit the removed page, they won’t end up at a dead end; rather, they’ll be redirected to a more relevant destination. If you’ve discontinued a product on your e-commerce site, a 301 redirect will reroute users to another page containing related products that are still available. 301 redirects also correct browser bookmarks, so you won’t risk losing traffic from regular visitors if you delete a page.
Meta robots no index tags
All websites contain pages that are valuable to users and administrators but have little SEO value. Take category and tag archive pages—while useful for users who want to read further posts on a certain topic or by a specific author, these pages create duplicate content, which only hurts SEO. Another example is back-end pages such as admin portals, which you obviously don’t want showing up in search results.
A great solution for these and similar instances is the meta robots no index tag. This tag allows search engines to crawl a page and (unless specified) follow links on it, but tells them not to index it for search purposes.
Here’s what a meta robots no index tag looks like in code form:

Notice how it says “follow” after “no index”—this tells crawlers that while they shouldn’t index the page, it’s OK for them to crawl it and follow any links therein. Allowing search engines to crawl your site’s pages is always best if possible, as it helps to avoid penalties. This is especially true with Google. In general, it’s better for your website to be transparent than clandestine, as Google tends to regard the latter with suspicion.
One final note: An alternate solution for multiple homepage iterations
Canonical tags are one way to solve the issue of multiple iterations of your homepage, but you can also do this via your Google search console settings. In the preferred domain and parameter handling area, you can specify which URL is the definitive one for your homepage. However, while this provides a quick fix, keep in mind that its effect is limited to Google—it won’t impact traffic from other search engines.
To learn more about small business SEO and digital marketing, read our other blog posts.
Want to revamp your business website or launch a digital marketing campaign? We can help!